de l´Information et
de la Communication pour
l´Éducation et la Formation
version à télécharger (pdf)
Volume 24, 2017
Article de recherche
Numéro Spécial
Recherches actuelles sur les MOOC
|
Contact : infos@sticef.org |
Simulation et validation de tests adaptatifs dans les MOOC
1. Introduction1.1. ContexteDans les cours en ligne, particulièrement les MOOC, la diversité des profils des apprenants et leur nombre sont tels qu'il est difficile pour un enseignant de répondre aux besoins de chacun d'entre eux. En effet, les étudiants qui se rendent sur un MOOC proviennent de différents pays, ont différents âges et parcours, et ont ainsi emmagasiné une variété de connaissances susceptible de diversifier leurs usages. Contrairement à un cours en classe, où les professeurs ont conscience des connaissances que les élèves sont censés avoir accumulées dans le passé, la pluralité des profils rend cette tâche impossible dans un MOOC. Or, lorsqu’ils arrivent sur un MOOC, nombre de ces apprenants se posent plusieurs questions initiales : 1) Que dois-je savoir pour commencer ce cours (c'est-à-dire, est-ce que je maîtrise tous les prérequis) ? 2) Existe-t-il d'éventuelles parties du cours dont je n’ai pas besoin ? Ainsi, alors que le cours est construit de façon séquentielle, il peut arriver que certains apprenants le parcourent dans un ordre qui leur est propre (Cisel, 2016). Afin que l'apprenant puisse répondre lui-même à ces questions initiales, le cours comprend habituellement sur la page d'inscription une section qui inclut la liste des prérequis à maîtriser afin de bénéficier de ce cours, ainsi que le programme du cours. Mais les élèves ne sont pas ceux qui sont le plus à même d'évaluer leurs connaissances (Eva et al., 2004), ainsi il serait préférable d’évaluer ces connaissances au moyen d'un test. Afin de ne pas solliciter l'apprenant avec trop de questions dès son arrivée sur le MOOC, il est préférable de poser aussi peu de questions que possible. C'est pourquoi il nous semble particulièrement utile de proposer un diagnostic adaptatif pour éliciter les connaissances de l'apprenant, afin de déterminer et lui indiquer les composantes de connaissances qu'il connaît déjà, mais aussi celles qui lui font défaut et qu'il doit maîtriser pour pouvoir bénéficier du cours. Une fois ces lacunes identifiées, il est envisageable de les fournir à un système de recommandation intégré à la plateforme de MOOC qui proposerait à l’apprenant des ressources pour les combler. Construire un tel diagnostic manuellement serait coûteux pour le professeur qui doit déjà préparer ses cours et les tests de validation pour obtenir le certificat. Nous préférons tirer parti du travail déjà fourni par le professeur et d’une représentation minimale du cours pour automatiser cette tâche. De plus, a priori, rien ne permet à l’enseignant d’affirmer qu’un test adaptatif réalise un diagnostic vraisemblable de l’apprenant. Nous montrons ainsi dans cet article qu'il est possible de construire des modèles de tests adaptatifs avec la simple donnée d'une représentation du cours, et de la valider à partir d’un historique de réponses à un test classique, selon une approche de crowdsourcing (Doan et al., 2011). Ainsi, une session du MOOC permet de récolter des données à partir desquelles on peut valider un diagnostic adaptatif automatique d'élicitation des connaissances, qui pourra être proposé aux apprenants s'inscrivant sur la session suivante du MOOC. Nous commençons par exposer nos hypothèses de recherche, puis nous expliquons ce qu'est un modèle de test adaptatif ainsi que les données qu'il requiert dans notre contexte. Enfin, nous proposons une méthodologie de validation d’un modèle de test adaptatif dans un MOOC et, à titre d'exemple, nous l'appliquons aux données d'un MOOC de mathématiques de Coursera. 1.2. HypothèsesNous supposons que le niveau de l’apprenant n’évolue pas après qu’il a répondu à une question. Sur les plateformes de MOOC usuelles (edX, Coursera), l’apprenant ne reçoit son feedback qu’à l’issue du test, ce qui rend cette hypothèse raisonnable. Nous supposons également que les questions sont posées une par une à l’apprenant, et qu’il ne peut pas modifier ses réponses précédentes. Nous prenons en compte le fait que l’apprenant puisse faire des erreurs d’inattention, ou deviner une bonne réponse par chance. En effet, les réponses des candidats à un test ne reflètent pas nécessairement leur maîtrise du sujet. 2. Tests adaptatifs2.1. PrincipeLes modèles de tests adaptatifs profitent du fait que les questions (aussi appelées items) sont administrées par une machine électronique (ordinateur, téléphone) afin de choisir la question suivante en fonction des réponses précédentes. Ils reposent sur deux fonctions : - un critère de terminaison, indiquant la fin du test ; - un critère de sélection de l'item suivant. Ainsi, le processus d'un test adaptatif peut se décrire de la façon simple suivante : - Tant que le critère de terminaison n'est pas vérifié, • Choisir la question maximisant le critère de sélection de l’item suivant ; • La poser au candidat ; • Enregistrer le résultat du candidat. Les tests adaptatifs permettent de garantir une bonne mesure tout en réduisant le nombre de questions (Lan et al., 2014). Par exemple il est plus économique de ne pas poser des questions trop difficiles tant que les questions plus faciles n'ont pas été résolues, et de ne pas poser de questions dont les composantes requises semblent déjà maîtrisées. C'est en effet un moyen d'obtenir des tests plus courts et plus personnalisés, parfois même capables de faire un retour à l'apprenant sur les points à retravailler. Cette manière d'administrer des tests n'est pas nouvelle. Les travaux sur les tests adaptatifs remontent à (Kingsbury et Weiss, 1983) et sont aujourd'hui utilisés en pratique par des tests tels que le GMAT (Graduate Management Admission Test) (Rudner, 2010) ou le GRE (Graduate Record Examination) pouvant accueillir des centaines de milliers d'étudiants (GMAC, 2013). Ils reposent sur un modèle de l'utilisateur qui permet de calibrer automatiquement le niveau des questions étant donné un historique de réponses. Ainsi, il est possible d'utiliser tout l'historique du passage du test pour poser des questions de façon adaptative. On distingue alors les tests à vocation sommative, qui ne renvoient généralement à l'apprenant qu'un score à l'issue du test, des tests à vocation formative, qui font un retour plus riche permettant à l'apprenant de s'améliorer. Ce n'est que depuis récemment (Huebner, 2010) que l'on s'intéresse à faire des tests formatifs adaptatifs, qui font un retour à l'apprenant à l'issue du test sous la forme de points maîtrisés ou non. Différents modèles de tests adaptatifs ont été proposés dans diverses communautés, ils sont comparés dans (Vie et al., 2017). Certains modèles requièrent un historique de passage pour être administrés, d’autres non. Dans cet article, la problématique qui nous intéresse est la suivante : quels modèles de tests adaptatifs choisir dans le cadre d’un MOOC, et comment les valider empiriquement sur des données existantes ? 2.2. Tests formatifs basés sur une Q-matrice, lien entre questions et composantes de connaissanceDéfinie par (Tatsuoka, 1983),
la q-matrice est une représentation minimale des composantes mises en
œuvre dans un test. Chaque question est liée à une ou
plusieurs composantes de connaissances mises en œuvre pour la
résoudre. On peut donc la représenter par une matrice binaire de
taille Il peut être fastidieux de remplir la q-matrice lorsqu'un test comporte beaucoup de questions. Certaines approches tentent de la calculer automatiquement, par exemple un algorithme de factorisation de matrices positives est utilisé par (Desmarais, 2011) pour extraire des paquets de questions qui semblent appartenir à un même groupe, afin de permettre une interprétation a posteriori. Cette méthode était déjà couramment utilisée afin d'extraire automatiquement des thèmes interprétables d'un corpus de texte, d'où sa pertinence appliquée à notre problème. À partir d’une q-matrice, il est possible de proposer des
modèles de diagnostic formatif. Par exemple, le modèle DINA (Junker et Sijtsma, 2001) consiste à ajouter à la q-matrice des paramètres
d’inattention (slip) Le modèle DINA a été mis en œuvre dans des tests
adaptatifs (Cheng, 2009) où tout au long du test on met à jour une distribution de
probabilité Si après
Par exemple, si l’apprenant a les connaissances requises, il peut soit
donner la bonne réponse en ne faisant pas d’erreur
d’inattention (résultat Le critère de terminaison est déclenché lorsqu’on
a identifié un état latent avec probabilité
supérieure à un certain seuil Pour choisir la question suivante, il est possible de quantifier formellement
l'information que chaque question peut apporter, de façon à
choisir la question la plus discriminante. En théorie de l'information,
une manière de représenter l'incertitude est l'entropie. Pour une
variable aléatoire Par exemple, une pièce parfaitement équilibrée peut
prendre la valeur Pile avec probabilité 50 % et Face avec la même
probabilité, ainsi son entropie est de
11, tandis qu'une autre pièce
pouvant prendre la valeur Pile avec une probabilité de 90 % aura une
entropie de 0,472. La pièce
équilibrée est donc celle d'incertitude maximale. On notera
également Le critère de sélection de l’item suivant consiste donc
à choisir la question
où Ainsi, avec cette probabilité, l’entropie va être mise
à jour en prenant en compte la réponse correcte de
l’apprenant. Avec la probabilité Le modèle DINA a ainsi été mis en œuvre pour des
tests adaptatifs, mais le nombre d’états latents possibles est 2.3. Représentation minimale des connaissances par un graphe de prérequisLa théorie des espaces de connaissances (Falmagne et al., 2006) suppose que l'on a accès à une donnée du cours qui est une
représentation hiérarchique des composantes de connaissance.
Celle-ci est sous la forme d'un graphe Cette structure permet de réduire drastiquement le nombre
d’états latents possibles ( Ce modèle de tests adaptatifs a été utilisé dans la plateforme ALEKS (Kickmeier-Rust et Albert, 2015) et (Desmarais et Baker, 2012) et dans le MOOC RealizeIt (Lynch et Howlin, 2014). Toutefois, il ne considère pas de paramètres d’inattention et de chance. Le modèle de hiérarchie sur les attributs (Leighton et al., 2004) permet de combiner q-matrice (dont paramètres d’inattention et de chance) et graphe de prérequis, et c’est donc celui que nous avons retenu pour notre expérience. Il est possible de calibrer les paramètres d’inattention et de chance à partir d’un historique de réponses, ou de les spécifier manuellement. L’observation du graphe de prérequis fournit une intuition géométrique sur le fait que certaines questions sont plus informatives que d'autres. Par exemple, poser une question reliée à une composante qui n'a pas d'arc sortant mais beaucoup de nœuds prérequis est peu avantageux car la probabilité que l'étudiant la maîtrise est faible, ainsi l’apprenant a de fortes chances de ne pas y répondre correctement et cela apportera peu d’information sur son état latent. Afin d'illustrer cette approche, nous présentons deux exemples de test
adaptatif, pour lesquels on supposera que pour toute question Exemple 1. Supposons que l’on ait, dans notre
représentation du domaine, trois composantes de connaissance A, B, et C
liées par les relations de prérequis A→B et B→C.
Ainsi, l’ensemble des états possibles parmi lesquels peut se
trouver l’apprenant est soit 000 (il ne maîtrise rien), soit 100
(seulement A), soit 110 (seulement A et B) soit 111 (il maîtrise tout). Il
n’y a pas d’autre état latent possible, étant
donné les relations de prérequis. Il y a autant de chances pour
que l’apprenant se trouve dans chacun de ces cas, donc - on a 75 % de chance d’observer une réponse correcte et de déduire qu’il maîtrise la composante A, et alors il ne reste plus que 3 états possibles (100, 110, 111) avec même probabilité 0,33, soit une entropie de 1,6 ; - on a 25 % de chance d’observer une réponse incorrecte et déduire qu’il ne maîtrise rien : 000, avec probabilité 1, soit une entropie de 0. L’entropie moyenne procurée par le fait d’administrer la
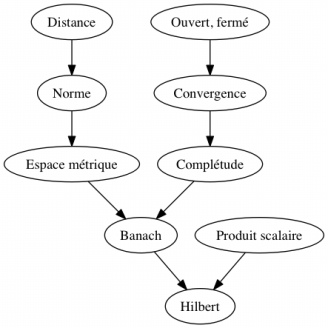
question A est donc Exemple 2. Si l'on considère le graphe de prérequis de la figure 1 et que l'apprenant maîtrise toutes les notions sauf Banach et Hilbert, un test minimisant l'entropie à chaque étape et s'arrêtant lorsque l’état latent de l’apprenant a été identifié avec une probabilité de 95 % se déroulera comme suit : - Q1. Est-ce que l'apprenant maîtrise « Produit scalaire » ?3 - Oui. - Q2. Est-ce que l'apprenant maîtrise « Convergence » ? - Oui. - Q3. Est-ce que l'apprenant maîtrise « Espace métrique » ? - Oui. À cet instant du test, la distribution de probabilité vaut 0 pour chaque état latent, sauf pour les quatre suivants qui ont la même probabilité 0,25 : • l’apprenant maîtrise tout ; • l’apprenant maîtrise tout sauf Banach, Complétude, Hilbert ; • l’apprenant maîtrise tout sauf Banach, Hilbert (il s’agit du bon état latent à identifier) ; • l’apprenant maîtrise tout sauf Hilbert. Si la suite du test est : - Q4. Est-ce que l'apprenant maîtrise « Banach » ? - Non. - Q5. Est-ce que l'apprenant maîtrise « Complétude » ? - Oui. Alors, l'apprenant maîtrise Produit scalaire, Distance, Norme, Ouvert/fermé, Complétude, Produit scalaire, mais pas Banach, Hilbert : c’est l’état latent le plus probable étant donné les réponses qu’il a données, ainsi que le graphe de prérequis. Ainsi, 5 questions ont été posées au lieu de 9 afin de déterminer l'état mental de l'apprenant et lui faire un retour.
Figure 1 • Un exemple de graphe de prérequis 3. Méthodologie de simulation et de validation d’un test adaptatif dans un MOOCTous les modèles de tests adaptatifs présentés précédemment sont habituellement validés sur des données simulées. Dans cet article, nous proposons une méthode automatisée pour valider des tests adaptatifs sur des données réelles issues d’un MOOC. Un MOOC se compose habituellement de chapitres constitués de sections au terme desquelles un quiz est proposé pour que l’apprenant puisse vérifier ses connaissances. Le plus souvent, l'apprenant peut en cas d'échec repasser le quiz, de façon limitée ou illimitée. Pour pouvoir faire un retour utile à l’apprenant, il faut considérer des modèles formatifs de test, qui s’appuient sur une q-matrice. Il faut donc spécifier le lien entre chaque question et les différentes composantes de connaissances développées dans le cours qu’elle évalue. Un test adaptatif basé sur le modèle DINA peut donc être initié. S’il y a un grand nombre de composantes de connaissances, il faut spécifier des relations de prérequis entre les composantes de connaissances, potentiellement à l’aide du squelette du cours, afin de réduire la complexité du problème. Nous suggérons donc le modèle de hiérarchie sur les attributs dans ce cas. 3.1. Données mises en œuvre pour la validationAfin de valider un modèle de test adaptatif formatif à partir de données réelles, nous avons besoin des éléments suivants : - le passé des notes des utilisateurs sur la
plateforme : un ensemble de motifs de réponse binaires (vrai ou
faux), sous la forme - une représentation des composantes de connaissances mises en œuvre dans le cours ; - la q-matrice : un lien entre chaque question et les composantes de connaissances qu'elle requiert. En cours de test, les informations que nous avons sur un apprenant sont : - le résultat (vrai ou faux) à chaque question que le système lui a posée ; - une estimation de la maîtrise par le candidat de chaque composante de connaissance. 3.2. Simulation et validationLe but est de poser un minimum de questions à chaque apprenant, c’est-à-dire révéler certaines composantes de son motif de réponse de façon adaptative, et de prédire les composantes restantes du motif de réponse. Deux métriques nous permettent de valider le modèle de test adaptatif que nous avons choisi. La première est le nombre moyen de questions avant arrêt du test (appelé temps de convergence moyen), c'est-à-dire avant que le critère de terminaison soit validé. La deuxième est le nombre de prédictions incorrectes (appelé erreur de prédiction), car il faut vérifier que le test converge vers un diagnostic qui est vraisemblable. Une fois le test terminé, à partir de l’état latent identifié, on compte le nombre de prédictions incorrectes du modèle de test adaptatif sur les questions non posées à l’apprenant pendant le test, afin d'évaluer si le diagnostic effectué par le modèle en peu de questions correspond bien aux données observées. 3.3. AjustementsCependant, sur un MOOC, les apprenants ne répondent pas à toutes les questions : comment considérer les entrées manquantes ? De plus, lorsque plusieurs essais sont enregistrés pour un couple apprenant/question, on peut choisir de considérer le premier ou celui de score maximum (Bergner et al., 2015). Dans notre cas, nous avons considéré à chaque fois le premier essai, pour minimiser le risque que l’apprenant devine la bonne réponse. Si l’apprenant n’a pas essayé de répondre à la question, nous comptons une réponse fausse. Dans les données des cours en ligne, on peut en effet supposer que si un apprenant a répondu à une question d’un quiz mais pas à d’autres questions issues du même quiz, c’est qu’il n’en connaît pas la réponse. 4. Mise en œuvre sur des données réelles de MOOCNous avons testé, sur de véritables données de MOOC issues d'un cours d'analyse fonctionnelle4, un modèle de test adaptatif basé sur le modèle de hiérarchie sur les attributs.. 4.1. Quelques données quantitativesLe cours a accueilli 25354 inscrits. À partir de toute la base de données SQL du MOOC, nous avons pu extraire les tests présentés dans le tableau 1. Tableau 1 • Tests extraits du MOOC d’analyse fonctionnelle
Le nombre d’étudiants – et donc de réponses aux questions – a diminué par abandon au fil du temps. Afin de simplifier l'étude tout en conservant un grand nombre de réponses, nous avons considéré le graphe de prérequis de la figure 1 et nous avons choisi un sous-ensemble de 9 questions tirées des quiz 1 à 4 du MOOC. Cela nous a permis de construire une matrice de motifs de réponse binaires de 37135 étudiants sur ces 9 questions portant sur les 9 composantes de connaissance Banach, Complétude, Convergence, Distance, Espace métrique, Hilbert, Norme, Ouvert et fermé, Produit scalaire. Chaque question a été choisie pour couvrir une composante de connaissance (et toutes celles qui sont nécessaires à sa maîtrise), ainsi chaque question correspond à un nœud du graphe de prérequis. Le nombre de motifs de réponse de chaque type est donné dans le tableau 2 et sa non-uniformité laisse entendre qu'il existe des corrélations entre les réponses aux questions (sinon, le nombre d'occurrences serait le même d'un motif de réponse à un autre). Tableau 2 • Les 30 motifs de réponse les plus fréquents pour le jeu de données extrait du MOOC d'analyse fonctionnelle
4.2. ValidationLe modèle n’ayant pas besoin de données existantes pour administrer des tests adaptatifs, il n’y a pas de données d’entraînement : tous les apprenants du jeu de données sont des apprenants de test. Pour simplifier notre analyse, nous avons initialisé tous les
paramètres d’inattention Pour chaque étudiant de notre jeu de données, nous simulons une interaction avec le modèle de test adaptatif qui consiste à choisir la question réduisant le plus l’incertitude (entropie) sur cet étudiant. Dès qu'on aboutit à une distribution de probabilité pour laquelle un état latent a une probabilité supérieure ou égale à 95 %, le test s'arrête. Cela permet de déterminer le nombre moyen de questions avant arrêt, ainsi que le nombre de prédictions incorrectes. Les résultats sont donnés dans le tableau 3. Tableau 3 • Métriques principales pour la validation du modèle de test adaptatif sur les données du MOOC d'analyse fonctionnelle
4.3. DiscussionLa valeur de robustesse Une plus grande valeur de robustesse Pour administrer un tel test, seul le graphe de prérequis est nécessaire, il n'y a pas besoin d’avoir déjà accès à des réponses d’apprenants. En revanche, pour vérifier si un modèle de test adaptatif fonctionne, il faut avoir accès aux réponses des apprenants. De telles traces peuvent également permettre de calibrer les paramètres d’inattention et de chance (donc de robustesse) des questions, et éventuellement de déceler des erreurs d’énoncé ou des questions trop faciles, à cause des réponses proposées en QCM par exemple. 5. Conclusion et perspectivesDans cet article, nous avons fait un état de l’art des modèles de tests adaptatifs et présenté une méthode pour les valider sur des données réelles. Nous l’avons mise en œuvre sur des données réelles issues d’un MOOC pour montrer que le modèle de hiérarchie sur les attributs (Leighton et al., 2004) peut réduire le nombre de questions posées tout en garantissant la fiabilité du test. Ce modèle se distingue de ceux utilisés en psychométrie, tels que le modèle de Rasch, car il ne nécessite pas de données existantes pour fonctionner et permet de faire un retour à l'étudiant sur les points non maîtrisés. À la fin du test, il est ainsi possible d’indiquer à l’apprenant : « Voici les prérequis qui semblent vous faire défaut », et éventuellement le rediriger vers des contenus qui peuvent l’aider à y remédier. Le fait de nommer ce que l’apprenant ne sait pas lui permet de pouvoir choisir comment acquérir ses connaissances, sur le cours ou par d’autres moyens. Il est également possible d’identifier les points forts des apprenants et de leur permettre de sauter d’éventuelles parties du cours consistant en des rappels. Afin d’étendre la recherche présentée dans cet article, il faudrait étudier le nombre de questions nécessaires à l’arrêt du test, ainsi que la pertinence du diagnostic obtenu en fonction de différentes valeurs du seuil pour le critère de terminaison (ici, nous n’avons considéré que 95 %). C’est l’objet de nos travaux futurs. Nous avons montré comment un modèle simple tel que celui de hiérarchie sur les attributs où tous les paramètres d’inattention et de chance sont rassemblés en un unique paramètre de robustesse permettait déjà de réduire le nombre de questions de façon satisfaisante. Pour aller plus loin, il faudrait essayer de calibrer automatiquement les paramètres d’inattention et de chance à partir d’une partie de la population de l’historique afin de voir si le modèle résiste davantage aux erreurs des apprenants. Dans certains domaines moins procéduraux que les mathématiques, comme les langues, le graphe de prérequis peut être difficile à construire. Il serait bon de pouvoir, à partir des données des apprenants, suggérer des modifications du graphe. Un modèle de diagnostic de connaissances permettant d’exprimer le fait qu’une composante de connaissances puisse intervenir plus ou moins dans la résolution d’une question est présenté dans (Vie et al., 2016). La représentation des composantes de connaissances à diagnostiquer sous la forme d'un graphe de prérequis peut être vue comme une ontologie minimale. D'autres modèles de tests non adaptatifs considèrent des ontologies pour la représentation des connaissances, tels que (Mandin et Guin, 2014). Des variantes adaptatives pourraient être développées pour réduire le nombre de questions, et de tels modèles permettraient d’enrichir le diagnostic rendu à l’apprenant à l’issue du test. RemerciementsNous remercions John Cagnol de nous avoir communiqué la base de données de son cours sur la plateforme Coursera et Benoît Choffin pour ses commentaires. Ce travail est soutenu par l'Institut de la Société Numérique de Paris-Saclay, financé par l'IDEX Paris-Saclay, ANR-11-IDEX-0003-02.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Référence de l'article :Jill-Jênn VIE, Fabrice POPINEAU, Éric BRUILLARD, Yolaine BOURDA, Simulation et validation de tests adaptatifs dans les MOOC, Revue STICEF, Volume 24, numéro 2, 2017, DOI:10.23709/sticef.24.2.6, ISSN : 1764-7223, mis en ligne le 11/04/2018, http://sticef.org |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

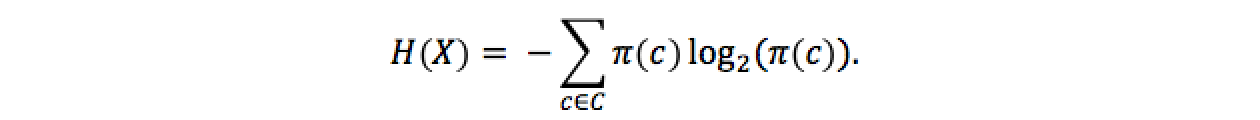
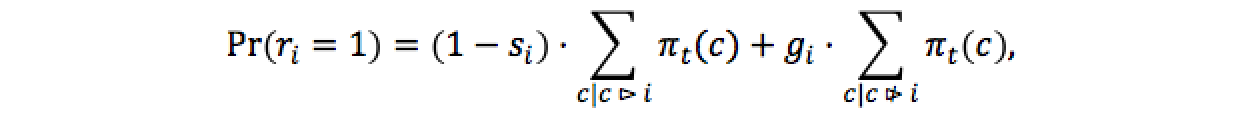

© Revue Sciences et Techniques de l'Information et de la Communication pour l'Éducation et la Formation